【DWH/モデリング】Type 2 SCDとdbtのSnapshotについて(SCD: Slowly Changing Dimension)
最近もっぱらdbt (data build tool) についての検証をしています。dbtは現時点だとなかなか日本語の情報があまりなく公式のドキュメントを頑張って読んで理解していく必要があるので、日本語にてこういう便利な機能があるよっていうのを紹介していく需要はあると思っています。(情報がないといってもすでにclassmethodさんのブログがいい感じに紹介してくれていますので参考になります。Youtubeの動画もあるのでそれも勉強になります。)
www.getdbt.com
今回はdbt自体の紹介をしつつも、その背景のモデリングに関する情報も織り交ぜていこうかと思います。
今回はSCD (Slowly Changing Dimension) について情報を整理しつつ、dbtを使うとこのようにSCDが実装されますという例を紹介をしようと思います。(環境はDocker Desktopを利用します。VSCodeの拡張機能を組み合わせるとすごく楽に開発できるのでよく利用しています。)
SCDについて
SCDはDWHなどの分析用に過去の時点の情報を蓄積していくデータストアなどで採用されるモデリング手法における重要な考え方です。SCDの話をする前にDWHのデータソースとなる業務システムのデータモデリング手法について触れておきましょう。
業務システムなどの特定の用途に特化したデータストアの場合は一般的には第3正規形を基本としたモデリング手法が採用されることが多いです。第3正規形は冗長なデータをなくしていることで整合性を取った形で更新をすることが得意です。冗長性を排除することでデータ容量を減らせるだけでなく、データの更新をする際の書き込みコストを大幅に削減することができます。一方で非正規化された形でデータを取得する際にJOINをするので、その際の計算コストが大きくなるというデメリットがあります。つまり、第3正規形は読み取り時の計算コストを払うという代償と引き換えに書き込み時のコストを最小限にするというメリットを享受していると言えます。
SCDにつなげるために言及しておきたいポイントは第3正規形におけるマスターデータの扱いです。主キー(他のテーブルから見たら外部キーの参照先)に紐づく属性値は多くの場合UPDATEによって更新されることが多いです(必ずしもそうでない場合もあります)。更新する際に過去の断面の情報を失うことになりますが、オペレーション上は最新のデータだけがあれば十分要件を満たせることが多いので問題になりません(必ずしもそうではない場合もありますが、その場合はちゃんと対策を取ると思うのでそれはまた別の話)。マスターデータ以外でも在庫情報など一つのキーに紐づく属性情報がトランザクション処理で細やかに更新されるデータもあります。業務システムの処理場は問題がないような場合でも、分析をする際には最新断面の情報以外にもある時点の状態を保持しておくことが必要になることが多いです。
つまり、分析用のデータモデルでは、分析対象のデータのある時点でのデータをそのまま写し取ったような「スナップショット」の保持を求められるということが多いということです。
このスナップショットを保持し続ける方法はいくつかありますが、その一つの方法がType 2 SCDです。どのように実装するかについてはdbtのところで紹介します。
(茶番)
…え、SCDってtype 2があるってことはほかのtypeがあるってことですか?
そうです。あります。ただ、知っておくべきはType 2だけでいいと個人的には思います。SCDの種類について触りだけ紹介しておきます。
Type 1はそもそも最新断面しか保持しないというものです。これでも問題ない場合があればこれが一番楽です。(何も考えなくていいので)
Type 2は履歴データをすべて保持していくことができるようにするもので、新しいレコードとして変更情報を追加していく方法です。いくつか実装の方法がありますが、個人的にはレコードの有効期限のメタデータを列として保持することで特定の時点のデータを判定することができるようにする方法がおすすめです。
Type 3は同じキーの属性値に過去のデータのための列を追加し、過去の時点のデータを保持する形です。Type 2よりも変更頻度が低いなどと特殊な場合では便利ですが汎用性の面でType 2の方が扱いやすいと思います。
他にもいろいろ組み合わせたものもあったりします。詳細は以下のWikipediaの記事に譲ります。(英語ですが…)
Slowly changing dimension - Wikipedia
ちなみにディメンションという言葉は「分析軸」みたいな意訳を与えてもいいと思っています。スタースキーマやディメンションモデリングと呼ばれるモデリング手法で登場するディメンションテーブルのスナップショットをどのように実現するかの考え方がSCDなのです。
dbtのSnapshotについて
dbtにおけるSnapshotに関しては公式ドキュメントを一度目を通してもらうとわかりますが、SCD Type 2を実現することでスナップショットを実現しています。
ドキュメントはこちら
Snapshots | dbt Docs
dbtの本質は共通の処理をマクロというものでくるんであげるというところにあります。SCDの実装はある程度定型化することができるので、dbtのコア機能としてマクロを提供してくれていると私は解釈しています。マクロで最小限の設定記述するだけで、転送してきたソースデータのコピーからSCD履歴データを蓄積していくことができるのでかなり便利です。
dbtのType 2 SCDの実装はタイムスタンプを利用したものです。汎用的に利用できる方法なのでありがたいです。
変更データを検出する戦略は2つ
①更新タイムスタンプを利用する【推奨】
ソースデータ側で保持している更新のタイムスタンプを利用する方法が選べます。この場合はそのカラムを指定するだけで大丈夫です。
もし、ソースデータ側に更新日付のタイムスタンプがない場合は裏技的な方法もあります。差分転送ができる場合はロードタイムスタンプを付与することができます。
②更新を検知するカラムを指定する
更新タイムスタンプがない場合に変更する可能性のあるカラムを指定してチェックすることで差分を検出するという方法もあります。
変更する可能性のあるカラムが多い場合はチェックする対象も増えるのでハッシュ関数などを利用してサロゲートキーのようなものを付与することで検知の負荷を下げることができるようになります。こちらも転送時あるいはモデルにて付与することが可能です。
付与されるメタデータ
①dbt_valid_from
スナップショットがインサートされたタイムスタンプが記録されます。異なるバージョンのレコードを指定する際に利用します。
②dbt_valid_to
この行が無効になったタイムスタンプが記録されます。
最新のレコードはNULLがセットされています。 COALESCE関数などでNULLをCURRENT_TIMESTAMPなどに置換してあげたりして使うこともあります。
③dbt_scd_id
各スナップショットにユニークキーが生成されます。(dbtが内部的に利用)
④dbt_updated_at
このスナップショットレコードがインサートされたときのソースデータのupdate_atカラムのタイムスタンプが記録されます。(dbtが内部的に利用)
dbtのsnapshotでのSCD type 2の実装例
開発環境を支える技術
参考程度にWindows10 Homeエディションを使っている私のPCでの開発環境を紹介します。実際に手を動かしてみたい場合は参考にしていただければ幸いです。Dockerが動かせる環境であればなんでもいいです。
・WSL2 (Ubuntu)
・Docker Desktop
・Visual Studio Code
⇒Remote Containerの拡張機能を使用します。
開発環境のイメージ
こんな感じでVSCodeでコードを書いて、動かす環境はDockerを利用します。ホスト環境を汚さないので楽です。

※PostgreSQLは13以上を使用しているので、12以下を使う場合は一部SQLで構文エラーがでます。適宜修正してください。
開発環境の構築
PostgreSQLコンテナを起動して初期セットアップをしていきます。
WSL2上でコマンドを実行します。
# PostgreSQLコンテナの起動 # dbt-postgres-testという名前のコンテナで作成 # ★環境変数POSTGRES_PASSWORDは環境ごとに変えること docker run --name dbt-postgres-test -e POSTGRES_PASSWORD=<パスワードに置換してください> -p 5432:5432 -d postgres
コンテナが起動したらコンテナ内に入ってデータベースに接続をします。
# Bashのセッションを起動 docker exec -it dbt-postgres-test bash # コンテナ内でのpsqlでの接続まで su - postgres psql
まずはデータベースとユーザを作成します。
--# Databaseを作成 CREATE DATABASE dbt LOCALE 'C' TEMPLATE template0; --# Roleを作成 CREATE USER dbt_user; --# パスワードを入力します \password dbt_user \q
作成したデータベースに接続しなおしてテスト用のデータを生成します。
psql -U dbt_user -d dbt
CREATE TABLE src_staffs ( staff_id INTEGER PRIMARY KEY , staff_name TEXT , area_name TEXT , updated_at TIMESTAMP ); CREATE TABLE src_sales ( sales_id INTEGER PRIMARY KEY , staff_id INTEGER , item_id INTEGER , amount INTEGER , updated_at TIMESTAMP ); CREATE TABLE src_items ( item_id INTEGER PRIMARY KEY , item_name TEXT , updated_at TIMESTAMP ); INSERT INTO src_staffs VALUES (1001, 'Jima', 'Tokyo', '2021-09-01 00:00:00'), (1002, 'Tomo', 'Tokyo', '2021-09-01 00:00:00'); INSERT INTO src_items VALUES (10001, 'item A', '2021-09-01 00:00:00'), (10001, 'item B', '2021-09-01 00:00:00'); INSERT INTO src_sales VALUES (1, 1001, 10001, 10, '2021-09-02 12:34:56'), (2, 1001, 10001, 20, '2021-09-06 12:34:56'), (3, 1001, 10002, 5, '2021-09-20 12:34:56'), (4, 1001, 10001, 2, '2021-09-29 12:34:56'), (5, 1002, 10001, 7, '2021-09-04 12:34:56'), (6, 1002, 10002, 10, '2021-09-15 12:34:56'), (7, 1002, 10001, 12, '2021-09-22 12:34:56'), (8, 1002, 10001, 21, '2021-09-26 12:34:56');
このソースデータを元にスナップショットの動作を確認していきます。
WSL2上でVSCodeを起動していきます。
# WSL2上でディレクトリを切って、VSCodeを起動 mkdir dev code dev
VSCodeを起動したらターミナルを開いていきます。( Ctrl + Shift + ` )
# dbtコンテナ用のディレクトリを作成 mkdir dbt-test cd dbt-test touch Dockerfile
Dockerfileに以下のコードを貼り付けます。(勉強がてら写経するのもありです。)
★dbtが1.0になった際にpipでプラグイン別にパッケージが個別にインストールされる形になったので、一部修正しました(2022/05/04)
FROM python:3.9
# Update and install system packages
RUN apt-get update -y && \
apt-get install --no-install-recommends -y -q \
git libpq-dev python3-dev && \
apt-get clean && \
rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
# Install DBT
RUN pip install --upgrade pip && \
pip install dbt-postgres
# Set environment variables
ENV PYTHONIOENCODING=utf-8
ENV LANG C.UTF-8
# Set WORKDIR and VOLUME
WORKDIR /usr/app
VOLUME /usr/app
EXPOSE 8080※2021/10/09時点だと「FROM python:latest」にするとdbtのインストールがおかしくなり動作しなくなります。(python 3.10が出たてほやほやで何かうまくいかないみたい…)
それでは、Remote Containerを利用してdbtのDockerコンテナを起動して開発環境を整えます。
①VSCode上でCtrl + Shift + Pを押してコマンドパレットを開きます。
②「Remote-Container: Open Folder in Container...」を選択します。
③先ほど作成したフォルダを選択します。
④Dockerfileから起動する選択肢(「From 'Dockerfile'」)を選択します。
これでコンテナ内に入りながらVSCodeでContainer内のファイルの編集ができるようになります。
# dbtプロジェクトの初期化 dbt init dbttest --adapter postgres # exampleは削除 rm -rf dbttest/models/example # profileの上書き cat << EOF > ~/.dbt/profiles.yml default: target: dev outputs: dev: type: postgres threads: 1 host: host.docker.internal port: 5432 user: dbt_user pass: "{{ env_var('DBT_PASSWORD') }}" dbname: dbt schema: public EOF
新しいbashのセッションを開いたら毎回これを入力するようにしてください。
# 環境変数にパスワードを入れます export DBT_PASSWORD=<dbt_userのパスワード>
Sourceの定義
dbtはELTのツールなので先ほど作成したテーブルはデータソースから転送されロードされたデータとして扱います。dbtではメタデータを含めて管理することでdocsに反映させるうえで便利です。
cd dbttest mkdir models/source touch models/source/source.yml
source.ymlは以下の通りに編集してください。
version: 2 sources: - name: snapshot-test description: Snapshotの練習 database: dbt schema: public tables: - name: src_staffs description: スタッフのマスタテーブル meta: type: master identifier: src_staffs columns: - name: staff_id description: スタッフのID【Primary Key】 tests: - unique - not_null - name: staff_name description: スタッフの名前 - name: area_name description: スタッフの担当エリア - name: updated_at description: レコードの更新日(挿入された日) - name: src_sales description: 売上のテーブル meta: type: transaction identifier: src_sales columns: - name: sales_id description: 売上のID tests: - unique - not_null - name: staff_id description: スタッフのID - name: item_id description: 売れた商品のID - name: amount description: 売れた商品の個数 - name: updated_at description: レコードの更新日(挿入された日) - name: src_items description: 商品のマスタテーブル meta: type: master identifier: src_items columns: - name: item_id description: 商品のID tests: - unique - not_null - name: item_name description: 商品の名前 - name: updated_at description: レコードの更新日(挿入された日)
Snapshotの定義
ここが本丸となるSnapshotの定義です。
# Snapshotの定義ファイルを作成 touch snapshots/snap_staffs.sql
snap_staffs.sqlは以下の通りに記述してください。タイムスタンプ戦略の際には以下の設定は必須です。
strategy='timestamp'
更新時のタイムスタンプを利用して差分を検知する戦略です
target_schema
Snapshotテーブルを配置するスキーマ
unique_key
元のレコードの主キー
updated_at
元のレコードの更新タイムスタンプの情報を保持しているカラム
{% snapshot snap_staffs %}
{{
config(
target_schema='public',
strategy='timestamp',
unique_key='staff_id',
updated_at='updated_at',
)
}}
select * from {{ source('snapshot-test', 'src_staffs') }}
{% endsnapshot %}
※Sourceを参照する際には以下の形式で指定します。
{{ source('sourceのグループの名前', 'sourceのテーブルの名前') }}
同じ要領でカラムのチェックでも検知戦略を試してみましょう
touch snapshots/snap_items.sql
snap_items.sqlは以下のように記述します。
strategy='check'
カラムの変化を利用して差分を検知する戦略です
target_schema
Snapshotテーブルを配置するスキーマ
unique_key
元のレコードの主キー
元のレコードの更新タイムスタンプの情報を保持しているカラム
{% snapshot snap_items %}
{{
config(
target_schema='public',
strategy='check',
unique_key='item_id',
check_cols=['item_name'],
)
}}
select * from {{ source('snapshot-test', 'src_items') }}
{% endsnapshot %}※checkの方式だとdbt_valid_fromの値がupdated_atカラムの情報を参照しなくなり、インサートされた時刻になるので扱いに注意!
modelの定義
最後にデータマートを定義しておきましょう。まずは説明を書いておきましょう(任意)
mkdir models/mart touch models/mart/mart.yml
mart.ymlは以下のように編集します。
version: 2 models: - name: mart_sales_db description: 売り上げのダッシュボード columns: - name: sales_id description: 売上のID - name: staff_id description: スタッフのID - name: item_id description: 商品のID - name: staff_name description: スタッフの名前 - name: area_name description: スタッフの担当エリア - name: item_name description: 商品の名前 - name: amount description: 売れた商品の個数
モデルの定義を作成します。
touch models/mart/mart_sales_db.sql
mart_sales_db.sqlは以下のように記述します。
{{
config(
materialized="view",
)
}}
SELECT
sr_sales.sales_id
, sr_sales.staff_id
, sr_sales.item_id
, sn_staffs.staff_name
, sn_staffs.area_name
, sn_items.item_name
, sr_sales.amount
FROM
{{ source('snapshot-test', 'src_sales') }} sr_sales
LEFT OUTER JOIN {{ ref('snap_staffs') }} sn_staffs
ON sr_sales.staff_id = sn_staffs.staff_id
AND sr_sales.updated_at BETWEEN sn_staffs.dbt_valid_from AND COALESCE(sn_staffs.dbt_valid_to, current_timestamp)
LEFT OUTER JOIN {{ ref('snap_items') }} sn_items
ON sr_sales.item_id = sn_items.item_id
AND sr_sales.updated_at BETWEEN sn_items.dbt_valid_from AND COALESCE(sn_items.dbt_valid_to, current_timestamp)
※Snapshotは他のモデルと同様にrefで参照可能です。
実行確認
①まずはSnapshotを取得します。
dbt snapshot
②モデルを実行します。
dbt run
③PostgreSQLコンテナに接続してテーブルを確認してみます。(実行結果付き)
dbt=> SELECT * FROM src_sales; sales_id | staff_id | item_id | amount | updated_at ----------+----------+---------+--------+--------------------- 1 | 1001 | 10001 | 10 | 2021-09-02 12:34:56 2 | 1001 | 10001 | 20 | 2021-09-06 12:34:56 3 | 1001 | 10002 | 5 | 2021-09-20 12:34:56 4 | 1001 | 10001 | 2 | 2021-09-29 12:34:56 5 | 1002 | 10001 | 7 | 2021-09-04 12:34:56 6 | 1002 | 10002 | 10 | 2021-09-15 12:34:56 7 | 1002 | 10001 | 12 | 2021-09-22 12:34:56 8 | 1002 | 10001 | 21 | 2021-09-26 12:34:56 (8 rows) dbt=> dbt=> SELECT * FROM src_items; item_id | item_name | updated_at ---------+-----------+--------------------- 10001 | item A | 2021-09-01 00:00:00 10002 | item B | 2021-09-01 00:00:00 (2 rows) dbt=> dbt=> SELECT * FROM snap_items; item_id | item_name | updated_at | dbt_scd_id | dbt_updated_at | dbt_valid_from | dbt_valid_to ---------+-----------+---------------------+----------------------------------+----------------------------+----------------------------+-------------- 10001 | item A | 2021-09-01 00:00:00 | b13aabcd19b1a73579c36d7783dfb199 | 2021-10-09 07:44:43.774351 | 2021-10-09 07:44:43.774351 | 10002 | item B | 2021-09-01 00:00:00 | 438fcc111c6ec5c05dda3f7fbc1266a1 | 2021-10-09 07:44:43.774351 | 2021-10-09 07:44:43.774351 | (2 rows) dbt=> dbt=> SELECT * FROM src_staffs; staff_id | staff_name | area_name | updated_at ----------+------------+-----------+--------------------- 1001 | Jima | Tokyo | 2021-09-01 00:00:00 1002 | Tomo | Tokyo | 2021-09-01 00:00:00 (2 rows) dbt=> dbt=> SELECT * FROM snap_staffs; staff_id | staff_name | area_name | updated_at | dbt_scd_id | dbt_updated_at | dbt_valid_from | dbt_valid_to ----------+------------+-----------+---------------------+----------------------------------+---------------------+---------------------+-------------- 1001 | Jima | Tokyo | 2021-09-01 00:00:00 | 6afc32cffd55557d3a691b34e22546fc | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 1002 | Tomo | Tokyo | 2021-09-01 00:00:00 | 3f276d9ad93653d6cd8116619c43e21d | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | (2 rows) dbt=> dbt=> SELECT * FROM mart_sales_db; sales_id | staff_id | item_id | staff_name | area_name | item_name | amount ----------+----------+---------+------------+-----------+-----------+-------- 1 | 1001 | 10001 | Jima | Tokyo | | 10 2 | 1001 | 10001 | Jima | Tokyo | | 20 3 | 1001 | 10002 | Jima | Tokyo | | 5 4 | 1001 | 10001 | Jima | Tokyo | | 2 5 | 1002 | 10001 | Tomo | Tokyo | | 7 6 | 1002 | 10002 | Tomo | Tokyo | | 10 7 | 1002 | 10001 | Tomo | Tokyo | | 12 8 | 1002 | 10001 | Tomo | Tokyo | | 21 (8 rows) dbt=>
これを見るとcheck戦略を取ったsnap_itemsのdbt_valid_fromのカラムがインサートされたタイムスタンプになっているので正しくJOINができなくなっています。こういった困った動作をしてしまうので、それを想定した下流のモデルにする必要があります。そのためdbtでは可能であればtimestampの戦略を選択するのがベストプラクティスとなっています。
設定(snap_items.sql)を直しておきましょう。
{% snapshot snap_items %}
{{
config(
target_schema='public',
strategy='timestamp',
unique_key='item_id',
updated_at='updated_at',
)
}}
select * from {{ source('snapshot-test', 'src_items') }}
{% endsnapshot %}
Snapshotは再構築ができないので注意が必要です。再構築する必要がある場合はスナップショットのテーブルをDropする必要があります。
DROP TABLE snap_items CASCADE;
スナップショットのテーブルを作成しなおして、一緒に削除されたビューも再作成しておきます。
dbt snapshot dbt run
もう一度確認してみます。(変更部分のみ)
dbt=> SELECT * FROM snap_items; item_id | item_name | updated_at | dbt_scd_id | dbt_updated_at | dbt_valid_from | dbt_valid_to ---------+-----------+---------------------+----------------------------------+---------------------+---------------------+-------------- 10001 | item A | 2021-09-01 00:00:00 | 194c38bc37e9de7c432e81adac2932d4 | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 10002 | item B | 2021-09-01 00:00:00 | 29cbcd9d9bb40cff442ac46d7ea6165b | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | (2 rows) dbt=> dbt=> SELECT * FROM mart_sales_db; sales_id | staff_id | item_id | staff_name | area_name | item_name | amount ----------+----------+---------+------------+-----------+-----------+-------- 1 | 1001 | 10001 | Jima | Tokyo | item A | 10 2 | 1001 | 10001 | Jima | Tokyo | item A | 20 3 | 1001 | 10002 | Jima | Tokyo | item B | 5 4 | 1001 | 10001 | Jima | Tokyo | item A | 2 5 | 1002 | 10001 | Tomo | Tokyo | item A | 7 6 | 1002 | 10002 | Tomo | Tokyo | item B | 10 7 | 1002 | 10001 | Tomo | Tokyo | item A | 12 8 | 1002 | 10001 | Tomo | Tokyo | item A | 21 (8 rows) dbt=>
Snapshotの更新の動作確認
以下を想定してみます。
・10月になり担当エリアを広げました。
・商品も追加し、商品名を変更しました。
・新たに売り上げのレコードも追加します。
①ソースデータを更新します
-- スタッフの担当エリアの変更 UPDATE src_staffs SET area_name = 'Osaka', updated_at = '2021-10-01 00:00:00' WHERE staff_name = 'Tomo'; -- 商品名の変更と商品の追加 UPDATE src_items SET item_name = 'gaming keyboard', updated_at = '2021-10-01 00:00:00' WHERE item_id = 10001; UPDATE src_items SET item_name = 'gaming mouse', updated_at = '2021-10-01 00:00:00' WHERE item_id = 10002; INSERT INTO src_items VALUES (10003, 'gaming monitor', '2021-10-01 00:00:00'); -- 売上レコードの追加 INSERT INTO src_sales VALUES (9 , 1001, 10001, 2 , '2021-10-01 12:34:56'), (10, 1001, 10003, 22, '2021-10-04 12:34:56'), (11, 1001, 10002, 6 , '2021-10-05 12:34:56'), (12, 1002, 10003, 3 , '2021-10-01 12:34:56'), (13, 1002, 10001, 8 , '2021-10-02 12:34:56'), (14, 1002, 10002, 13, '2021-10-05 12:34:56'), (15, 1002, 10001, 7 , '2021-10-07 12:34:56'), (16, 1002, 10003, 24, '2021-10-08 12:34:56');
②snapshotを更新します。
dbt snapshot
③PostgreSQLコンテナに接続してテーブルを確認してみます。(実行結果付き)
dbt=> SELECT * FROM src_sales; sales_id | staff_id | item_id | amount | updated_at ----------+----------+---------+--------+--------------------- 1 | 1001 | 10001 | 10 | 2021-09-02 12:34:56 2 | 1001 | 10001 | 20 | 2021-09-06 12:34:56 3 | 1001 | 10002 | 5 | 2021-09-20 12:34:56 4 | 1001 | 10001 | 2 | 2021-09-29 12:34:56 5 | 1002 | 10001 | 7 | 2021-09-04 12:34:56 6 | 1002 | 10002 | 10 | 2021-09-15 12:34:56 7 | 1002 | 10001 | 12 | 2021-09-22 12:34:56 8 | 1002 | 10001 | 21 | 2021-09-26 12:34:56 9 | 1001 | 10001 | 2 | 2021-10-01 12:34:56 10 | 1001 | 10003 | 22 | 2021-10-04 12:34:56 11 | 1001 | 10002 | 6 | 2021-10-05 12:34:56 12 | 1002 | 10003 | 3 | 2021-10-01 12:34:56 13 | 1002 | 10001 | 8 | 2021-10-02 12:34:56 14 | 1002 | 10002 | 13 | 2021-10-05 12:34:56 15 | 1002 | 10001 | 7 | 2021-10-07 12:34:56 16 | 1002 | 10003 | 24 | 2021-10-08 12:34:56 (16 rows) dbt=> dbt=> SELECT * FROM src_items; item_id | item_name | updated_at ---------+-----------------+--------------------- 10003 | gaming monitor | 2021-10-01 00:00:00 10001 | gaming keyboard | 2021-10-01 00:00:00 10002 | gaming mouse | 2021-10-01 00:00:00 (3 rows) dbt=> dbt=> SELECT * FROM snap_items; item_id | item_name | updated_at | dbt_scd_id | dbt_updated_at | dbt_valid_from | dbt_valid_to ---------+-----------------+---------------------+----------------------------------+---------------------+---------------------+--------------------- 10003 | gaming monitor | 2021-10-01 00:00:00 | 6a93a07151b2012b73e86eaf69c0aebb | 2021-10-01 00:00:00 | 2021-10-01 00:00:00 | 10001 | item A | 2021-09-01 00:00:00 | 194c38bc37e9de7c432e81adac2932d4 | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 2021-10-01 00:00:00 10002 | item B | 2021-09-01 00:00:00 | 29cbcd9d9bb40cff442ac46d7ea6165b | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 2021-10-01 00:00:00 10001 | gaming keyboard | 2021-10-01 00:00:00 | 45ea22fa9252cf59e6e1edcabb27590d | 2021-10-01 00:00:00 | 2021-10-01 00:00:00 | 10002 | gaming mouse | 2021-10-01 00:00:00 | 02dc77f4a1bee071d2a6e40d13804998 | 2021-10-01 00:00:00 | 2021-10-01 00:00:00 | (5 rows) dbt=> dbt=> SELECT * FROM src_staffs; staff_id | staff_name | area_name | updated_at ----------+------------+-----------+--------------------- 1001 | Jima | Tokyo | 2021-09-01 00:00:00 1002 | Tomo | Osaka | 2021-10-01 00:00:00 (2 rows) dbt=> dbt=> SELECT * FROM snap_staffs; staff_id | staff_name | area_name | updated_at | dbt_scd_id | dbt_updated_at | dbt_valid_from | dbt_valid_to ----------+------------+-----------+---------------------+----------------------------------+---------------------+---------------------+--------------------- 1001 | Jima | Tokyo | 2021-09-01 00:00:00 | 6afc32cffd55557d3a691b34e22546fc | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 1002 | Tomo | Tokyo | 2021-09-01 00:00:00 | 3f276d9ad93653d6cd8116619c43e21d | 2021-09-01 00:00:00 | 2021-09-01 00:00:00 | 2021-10-01 00:00:00 1002 | Tomo | Osaka | 2021-10-01 00:00:00 | 73617314bbe4b5f84934db52e5c58398 | 2021-10-01 00:00:00 | 2021-10-01 00:00:00 | (3 rows) dbt=> dbt=> SELECT * FROM mart_sales_db; sales_id | staff_id | item_id | staff_name | area_name | item_name | amount ----------+----------+---------+------------+-----------+-----------------+-------- 1 | 1001 | 10001 | Jima | Tokyo | item A | 10 2 | 1001 | 10001 | Jima | Tokyo | item A | 20 3 | 1001 | 10002 | Jima | Tokyo | item B | 5 4 | 1001 | 10001 | Jima | Tokyo | item A | 2 5 | 1002 | 10001 | Tomo | Tokyo | item A | 7 6 | 1002 | 10002 | Tomo | Tokyo | item B | 10 7 | 1002 | 10001 | Tomo | Tokyo | item A | 12 8 | 1002 | 10001 | Tomo | Tokyo | item A | 21 9 | 1001 | 10001 | Jima | Tokyo | gaming keyboard | 2 10 | 1001 | 10003 | Jima | Tokyo | gaming monitor | 22 11 | 1001 | 10002 | Jima | Tokyo | gaming mouse | 6 12 | 1002 | 10003 | Tomo | Osaka | gaming monitor | 3 13 | 1002 | 10001 | Tomo | Osaka | gaming keyboard | 8 14 | 1002 | 10002 | Tomo | Osaka | gaming mouse | 13 15 | 1002 | 10001 | Tomo | Osaka | gaming keyboard | 7 16 | 1002 | 10003 | Tomo | Osaka | gaming monitor | 24 (16 rows) dbt=>
おまけで集計版のビューを定義してみましょう。
touch models/mart/mart_sales_sumaray.sql
{{
config(
materialized="table",
)
}}
With stg_sales_detail AS (
SELECT
sr_sales.sales_id
, sr_sales.staff_id
, sr_sales.item_id
, sn_staffs.staff_name
, sn_staffs.area_name
, sn_items.item_name
, sr_sales.amount
, DATE_TRUNC('month', sr_sales.updated_at) AS sales_month
FROM
{{ source('snapshot-test', 'src_sales') }} sr_sales
LEFT OUTER JOIN {{ ref('snap_staffs') }} sn_staffs
ON sr_sales.staff_id = sn_staffs.staff_id
AND sr_sales.updated_at BETWEEN sn_staffs.dbt_valid_from AND COALESCE(sn_staffs.dbt_valid_to, current_timestamp)
LEFT OUTER JOIN {{ ref('snap_items') }} sn_items
ON sr_sales.item_id = sn_items.item_id
AND sr_sales.updated_at BETWEEN sn_items.dbt_valid_from AND COALESCE(sn_items.dbt_valid_to, current_timestamp)
)
SELECT
EXTRACT(month from sales_month) AS sales_month
, area_name
, staff_name
, item_name
, SUM(amount) AS SUM_amount
FROM
stg_sales_detail
GROUP BY
staff_name, area_name, item_name, sales_month
ORDER BY
1, 2, 3, 4
モデルを作成しましょう(特定のモデルを作成する際はオプションを指定します。)
dbt run --model mart_sales_sumaray
dbt=> SELECT * FROM mart_sales_sumaray ; sales_month | area_name | staff_name | item_name | sum_amount -------------+-----------+------------+-----------------+------------ 9 | Tokyo | Jima | item A | 32 9 | Tokyo | Jima | item B | 5 9 | Tokyo | Tomo | item A | 40 9 | Tokyo | Tomo | item B | 10 10 | Osaka | Tomo | gaming keyboard | 15 10 | Osaka | Tomo | gaming monitor | 27 10 | Osaka | Tomo | gaming mouse | 13 10 | Tokyo | Jima | gaming keyboard | 2 10 | Tokyo | Jima | gaming monitor | 22 10 | Tokyo | Jima | gaming mouse | 6 (10 rows) dbt=>
まとめとドキュメントについて
こんな感じでType 2 SCDが簡単に実装することができます。
最後にDocumentを生成してどんなモデルができたのか確認してみると理解が深まると思います。
Remote Containerではデフォルトでコンテナのポートが解放されていないので、dbt-testディレクトリ直下にある「.devcontainer」ディレクトリ直下の「devcontainer.json」に以下のポート開放の設定を追記します。
Developing inside a Container using Visual Studio Code Remote Development
"appPort": ["8080:8080"],
Remote Containerを再起動するとリビルドするように言われるのでリビルドします。docker psで確認するとポートが解放されていることがわかります。
リビルドしてしまったので、プロファイルを再度作成しておきます。パスワードも設定しましょう。
mkdir ~/.dbt cat << EOF > ~/.dbt/profiles.yml default: target: dev outputs: dev: type: postgres threads: 1 host: host.docker.internal port: 5432 user: dbt_user pass: "{{ env_var('DBT_PASSWORD') }}" dbname: dbt schema: public EOF export DBT_PASSWORD=<dbt_userのパスワード>
それでは、ドキュメントを生成してみましょう
dbt docs generate dbt docs serve
(表示されるまでちょっと時間かかるかも…)
こんな感じのホーム画面がでます。
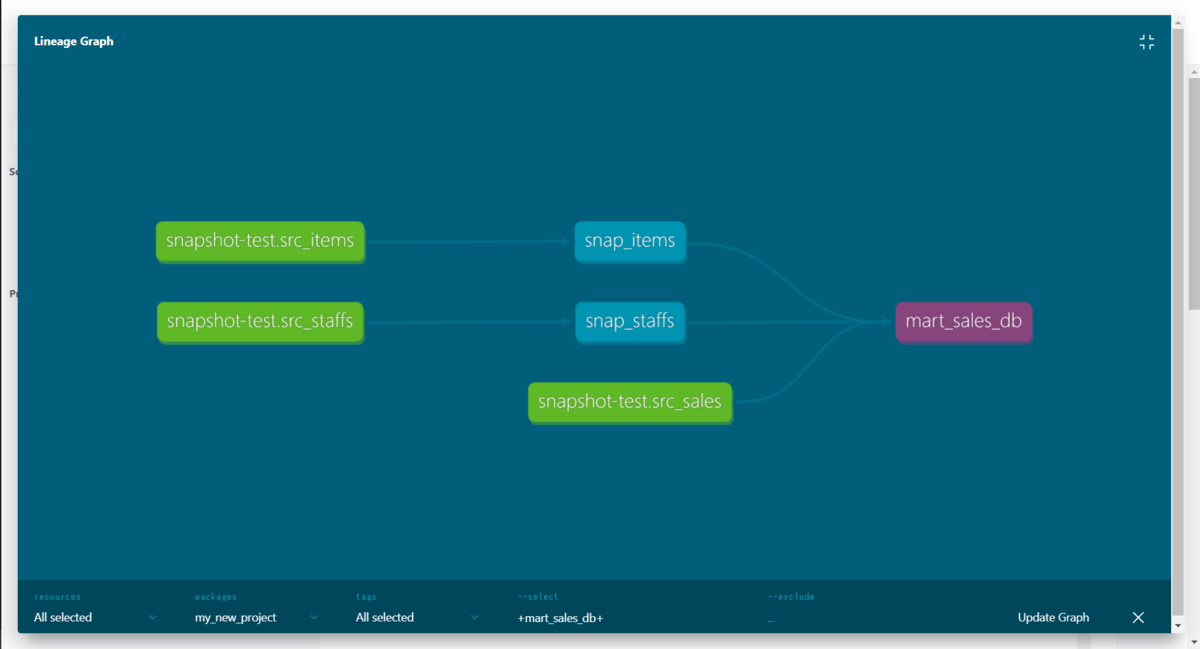
こんな感じのリネージを見れたりします。
こんな感じでSCDの実装を設定ファイルを書くだけでできるdbtは便利なツールだと思います。慣れるまで難しかったり、まだまだ成長していく段階のOSSだと思うので今後も追加機能に期待ですね。
まだまだマクロを使いこなしたりとか知らない機能もいっぱいあるので、今後も継続的に機能検証していきたいと思います。