【AWS/ECS/Fargate】Embulkのジョブをサーバレスに実行する基盤を作ってみるチュートリアル(パート2)
以下の記事のパート2です。
【パート1】開発環境の準備
【パート2】Embulkコンテナの作成・単体テスト(★本記事)
【パート3】ECSのタスク定義と動作確認
【パート4】Step Functionsで簡単に実行できるように設定する
Cloud9とRDSのセットアップとデータの登録などの下準備が完了した状態です。このパートではEmbulkのコンテナのビルド、ETLジョブの開発と単体テスト及びデプロイまでを行います。
目次
- 2-1) CodeCommitの作成とクローン
- 2-2) 設定ファイルやスクリプトをデプロイするS3バケットの作成
- 2-3) Embulkコンテナのビルド
- 2-4) ビルドしたコンテナイメージをECRに保存
- 2-5) Embulkの設定ファイルとスクリプトのコーディング
- 2-6) Embulkのコンテナを利用したETLジョブの実行(単体テスト)
- 2-7) CodePipelineでS3にスクリプトと設定ファイルをデプロイ
2-1) CodeCommitの作成とクローン
CodeCommitのリポジトリを作成します。マネジメントコンソールを開いてリポジトリを作成しましょう。
・リポジトリ名:datafound-embulk(好きな名前でいいです。)
出来上がったらCloud9側でクローンをしましょう(マネジメントコンソール上に表示されているコマンドを控えておくと楽です)。チュートリアルなので適当に設定していいです。
Cloud9のターミナルで以下のコマンドを実行します。(※<>は読み替えてください)
# git configで設定をする git --version git config --global user.name "<あなたの名前>" git config --global user.email <あなたの名前>@example.com # AWS credentialのヘルパーを有効化する git config --global credential.helper '!aws codecommit credential-helper $@' git config --global credential.UseHttpPath true # クローンする(コンソールからコピーしたコマンドに読み替えます) git clone https://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/<リポジトリ名>
クローンされたディレクトリが生成されていることを確認します。
2-3) Embulkコンテナのビルド
ETLジョブは比較的似たような処理を複数実行されることが多いです。そのため、今回は汎用的なコンテナイメージを作成します。処理毎に設定ファイルやスクリプトを個別に用意してコンテナイメージは使い回せるようにします。
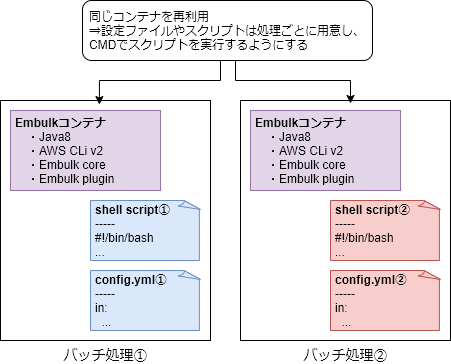
まずはDockerfileをコーディングしていきましょう。
★今回はヒアドキュメントで生成できるようにコマンド貼っておきます。手を動かして写経するのもありだと思います。(※<>は読み替えてください)
cd ~/environment/<git cloneしたディレクトリ> mkdir -p docker/postgres-postgres cd docker/postgres-postgres # Dockerfileを作成 cat << 'EOF' > Dockerfile FROM openjdk:8-slim ENV LANG=C.UTF-8 ENV PATH_TO_EMBULK=/opt/embulk ENV PATH=${PATH}:/opt/embulk # Change timezone RUN ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime RUN apt-get update && apt-get install -y curl unzip # AWS CLI install WORKDIR /tmp RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" RUN unzip awscliv2.zip RUN ./aws/install # Embulk install RUN mkdir -p ${PATH_TO_EMBULK} RUN curl --create-dirs -o ${PATH_TO_EMBULK}/embulk -L "https://dl.embulk.org/embulk-0.9.23.jar" RUN chmod +x ${PATH_TO_EMBULK}/embulk # install Embulk Plugin RUN embulk gem install embulk-input-postgresql RUN embulk gem install embulk-output-postgresql WORKDIR /app CMD [ "bash" ] EOF
次にdocker buildコマンドでビルドします。
# Build docker build -t embulk-0.9.23-postgres-postgres .
出来上がったイメージを確認します。
# 確認 docker image ls
このコンテナを使用した単体テストは設定ファイルやスクリプトを作成した後でやります。ここではまず先にレジストリへpushしておきます。
2-4) ビルドしたコンテナイメージをECRに保存
今回はECRをコンテナレジストリとして利用します。
まずはECRのレジストリを作成しましょう。
ESR(ECS、EKSと同じページ)のマネジメントコンソールを開きます。
「リポジトリを作成」を開きます。項目を入力したら作成しましょう。
・可視性設定:プライベート
・リポジトリ名:(好きなものでOK)
※その他は変えても変えなくてもいいです。
すぐに出来上がるのでリポジトリを開きます。
右上に「プッシュコマンドの表示」をクリックします。コンテナイメージをプッシュするまでに必要な手順をコンソールは教えてくれます。案内に従って進めましょう。(※<>は読み替えてください)
1. 認証トークンを取得し、レジストリに対して Docker クライアントを認証します。
Cloud9のターミナルで以下のコマンドを実行します。(※<>は読み替えてください)
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com
2. (Dockerイメージの構築はスキップします。)
3. 構築が完了したら、このリポジトリにイメージをプッシュできるように、イメージにタグを付けます。(※<>は読み替えてください)
docker tag embulk-0.9.23-postgres-postgres:latest <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/datafound-embulk:pg-pg # 確認 docker image ls
4. コンテナイメージをプッシュする(※<>は読み替えてください)
docker push <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/datafound-embulk:pg-pg
無事イメージが登録できました。続いてこのコンテナイメージを使ってETLジョブの開発と単体テストを実施しましょう!
2-5) Embulkの設定ファイルとスクリプトのコーディング
EmbulkはYAML形式でETLジョブの設定を行うことができます。プラグインを開発しているGitHubのReadmeを見れば各種パラメータの意味が分かります。
今回利用するプラグインのGitHubのリンクを貼っておきます。
・embulk-input-postgresql
https://github.com/embulk/embulk-input-jdbc/tree/master/embulk-input-postgresql
・embulk-output-postgresql
https://github.com/embulk/embulk-output-jdbc/tree/master/embulk-output-postgresql
また、Embulkはliquidテンプレートを利用できるので、認証情報などは環境変数に書いておいたり、共通の設定を外だししたりすることが可能です。
今回はSSMのパラメータストアに共通の設定や認証情報を保存して、スクリプトファイルでパラメータを取得して環境変数に取り込むようにします。
それでは、設定ファイルを書いていきましょう。(※<>は読み替えてください)
cd ~/environment/<git cloneしたディレクトリ> mkdir -p job/001-test_tbl cd job/001-test_tbl cat << 'EOF' > config.yml.liquid in: type: postgresql host: {{ env.SOURCE_HOST }} port: {{ env.SOURCE_PORT }} user: {{ env.SOURCE_USER }} password: {{ env.SOURCE_PASSWORD }} database: {{ env.SOURCE_DATABASE }} schema: {{ env.SOURCE_SCHEMA }} table: test_tbl incremental: true incremental_columns: - updated_at out: type: postgresql host: {{ env.TARGET_HOST }} port: {{ env.TARGET_PORT }} user: {{ env.TARGET_USER }} password: {{ env.TARGET_PASSWORD }} database: {{ env.TARGET_DATABASE }} schema: {{ env.TARGET_SCHEMA }} table: test_target_tbl mode: insert EOF
続いてスクリプトファイルです。スクリプトファイルはほとんど環境変数を設定しているだけです。別ファイルにしてもいいくらいです。
★
cat << 'EOF' > run.sh #!/bin/bash set -e # input関連の環境変数 export SOURCE_HOST=`aws ssm get-parameter --name "/embulk/source/postgresql/host" --query "Parameter.Value" --output text` export SOURCE_PORT=`aws ssm get-parameter --name "/embulk/source/postgresql/port" --query "Parameter.Value" --output text` export SOURCE_USER=poc_user export SOURCE_PASSWORD=`aws ssm get-parameter --name "/embulk/source/postgresql/poc_user" --with-decryption --query "Parameter.Value" --output text` export SOURCE_DATABASE=source export SOURCE_SCHEMA=public # output関連の環境変数 export TARGET_HOST=`aws ssm get-parameter --name "/embulk/target/postgresql/host" --query "Parameter.Value" --output text` export TARGET_PORT=`aws ssm get-parameter --name "/embulk/source/postgresql/port" --query "Parameter.Value" --output text` export TARGET_USER=poc_user export TARGET_PASSWORD=`aws ssm get-parameter --name "/embulk/target/postgresql/poc_user" --with-decryption --query "Parameter.Value" --output text` export TARGET_DATABASE=target export TARGET_SCHEMA=public # ジョブ固有の環境変数 export JOB_NAME=001-test_tbl # logディレクトの作成 mkdir ./log # ジョブの実行 embulk run -c config.diff.yml config.yml.liquid > ./log/embulk-result-${JOB_NAME}-`date +%Y%m%d-%H%M%S`.log aws s3 cp ./config.diff.yml s3://<バケット名>/job/${JOB_NAME}/config.diff.yml aws s3 cp ./log s3://<バケット名>/log/${JOB_NAME}/`date +%Y%m%d` --recursive exit 0 EOF
「set -e」があることによって、エラー時の後続の処理を停止することができます。
embulkコマンドのオプションで、差分更新を可能にするためにdiffファイルを指定している点に注目してください。
このdiffファイルをスクリプトや設定ファイルを保存しているS3に一緒に保存してあげて次回以降に一緒に取ってこれるようにしています。EC2などで実行する分にはわざわざS3に毎回putしておく必要はありませんが、毎回コンテナが破棄されるサーバレスでやる上で必要不可欠な仕組みです。
ちなみに、FargateでもEFSをサポートしているので、単純にEFSをマウントさせるという技も使えます。今回はCodeDeployで連携がしやすいという点で利点があるのでS3を使います。
2-6) Embulkのコンテナを利用したETLジョブの実行(単体テスト)
それでは先ほどビルドしたコンテナでスクリプトと設定ファイルの単体テストを実施しましょう。
コンテナとのローカルファイルのやりとりをしますが、細かいところは以下のサイトなどをご確認ください。
https://blog.amedama.jp/entry/2018/01/30/221546
まずはコンテナを起動しておきます。
docker run -it embulk-0.9.23-postgres-postgres:latest
★別のターミナルを開きます。
実行中のコンテナを確認して先ほど書いたファイルをコピーします。
# スクリプトや設定ファイルがあるディレクトリまで移動 cd ~/evironment/<クローンしたディレクトリ>/job/001-test_tbl ls -l # 実行中のコンテナを確認 docker ps # コンテナIDを置換してコピーを実施 docker cp . <コンテナID>:/app
これまではcloud9の環境だったので、権限はコンソールにログインしているユーザーと同等で特に意識はそこまでしていませんでした。
ただしコンテナの中に入ると今までの環境か異なり、IAMの権限が必要になってきます。今回はIAMユーザーを作成してそのクレデンシャルを登録します。
以下のIAMポリシーを作成します。(ポリシー名は何でもいいです。)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<バケット名>", "arn:aws:s3:::<バケット名>/*" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "ssm:GetParameter", "Resource": "arn:aws:ssm:ap-northeast-1:<アカウントID>:parameter/embulk/*" } ] }
作成したIAMポリシーを付与したIAMユーザーを作成します。作成したらクレデンシャルの情報を控えておきましょう。(ユーザ名は何でもいいです。)
クレデンシャルをコンテナの環境変数にセットします。(aws configureで設定してもいいと思います)
★dockerのコンテナ内で実行します
export AWS_ACCESS_KEY_ID=<アクセスキー> export AWS_SECRET_ACCESS_KEY=<シークレット> export AWS_DEFAULT_REGION=ap-northeast-1
それでは満を持してスクリプトを実行していきましょう。
ls -l chmod +x ./* ls -l ./run.sh
エラーが出たら頑張って修正しましょう。だいたいタイポしていたり、構文エラーが原因のことが多いです。
ターゲットDBを確認し、データが転送されている事を確認します。
ターゲットDBに接続して以下のSQLを実行します。
SELECT * FROM test_target_tbl;
ソース側のテーブルにデータを追加してもう一度やってみてもいいですが、これ以降はconfig.diff.ymlをS3からとってくる必要が出てくるECSでテストすることとしましょう。
ちなみに、config.diff.ymlはこんな感じになっています。
in: last_record: ['2021-09-19T14:40:30.601724'] out: {}
このlast_recordが差分転送のために必要な情報です。
2-7) CodePipelineでS3にスクリプトと設定ファイルをデプロイ
無事スクリプトファイルや設定ファイルが問題なく動作することが分かったのでCodeCommitにpushしましょう。
cd ~/environment/<git cloneしたディレクトリ> ls -l # コミット対象を追加 git add . # 確認 git status # コミット(コメントは適宜変えてください) git commit -m "add script and config in job/001-test_tbl" # プッシュ git push
※Dockerfile自体はスクリプト自体の実行には不要ですがセットでコミット対象としています。
続いて、マネジメントコンソールでCI/CDのパイプラインを作りましょう。
CodePipelineのマネジメントコンソールを開き、「パイプラインを作成する」をクリックします。
1. 【パイプラインの設定を選択する】
・パイプライン名:(好きなものでOK)
※ロールは新しく作るので大丈夫です。他の設定はいじらなくてもいいです。(意味が分かっていればいじってもOK)
2. 【ソースステージを追加する】
・ソースプロバイダー:AWS CodeCommit
・リポジトリ名:datafound-embulk(先ほど作成したリポジトリ名)
・ブランチ:master
※その他はデフォルトで大丈夫です。
3. 【ビルドステージを追加する】
ビルドは不要なのでスキップします。「ビルドステージをスキップ」をクリックします。(確認ウィンドウが出るのでそちらもスキップをクリック)
4. 【デプロイステージを追加する】
・デプロイプロバイダー:Amazon S3
・リージョン:アジアパシフィック(東京)
・バケット:(先ほど作成したS3バケットを選択)
・デプロイする前にファイルを抽出する:チェックする!
※S3 オブジェクトキー(デプロイパス)は入力しない
※追加設定はいじらなくていい
後はレビューして作成しましょう。
作成が完了すると、すぐに先ほどコミットしたイベントをベースにパイプラインが動いていきます。S3にファイルがデプロイされていることを確認してください。
以上でこのパートは終わりです。
このパートでは、ECSでタスクを実行するためにコンテナのビルドからコーディングと単体テスト、デプロイまで実施しました。
次のパートに続きます。