【AWS/ECS/Fargate】Embulkのジョブをサーバレスに実行する基盤を作ってみるチュートリアル(パート4)
以下の記事のパート4です。
【パート1】開発環境の準備
【パート2】Embulkコンテナの作成・単体テスト
【パート3】ECSのタスク定義と動作確認
【パート4】Step Functionsで簡単に実行できるように設定する(★本記事)
ECSでのタスクの実行確認までできました。最後にStep Functionsでより簡単にジョブを実行できるようにして完了です!頑張りましょう~(*^▽^*)
目次
4-1) 動作確認用ののデータを投入
差分更新用のデータを投入しておきます。
ターゲットデータベースに接続して以下のSQLを実行します。
UPDATE test_tbl SET payload = 'update increment test', updated_at = current_timestamp WHERE id = 1; -- 確認 SELECT * FROM test_tbl;
updateでも増分更新ができるかどうかを見てみましょう。(output側はinsertモードなので別の行として連携されるはずです。)
4-2) Srep Functionsの設定
Step Functionsのマネジメントコンソールを開き左ペインからステートマシンを選択してステートマシンのページを開きます。
「ステートマシンの作成」をクリックします。
1. 【作成方法を選択】
「ワークフローを視覚的に設計」を選択(Srep Functions Workflow Studio)
・タイプ:標準
※基本的にバッチ処理は標準を選択します。ストリーミングデータ処理やマイクロサービスなどの短時間(5分以内)で頻発する処理だけExpressを選択します(Expressの方が制限が多いです。)。
2. 【ワークフローを設計】
①左ペインの「アクション」タブの中から「Amazon ECS RunTask」をドラッグ&ドロップで中央の点線内に配置
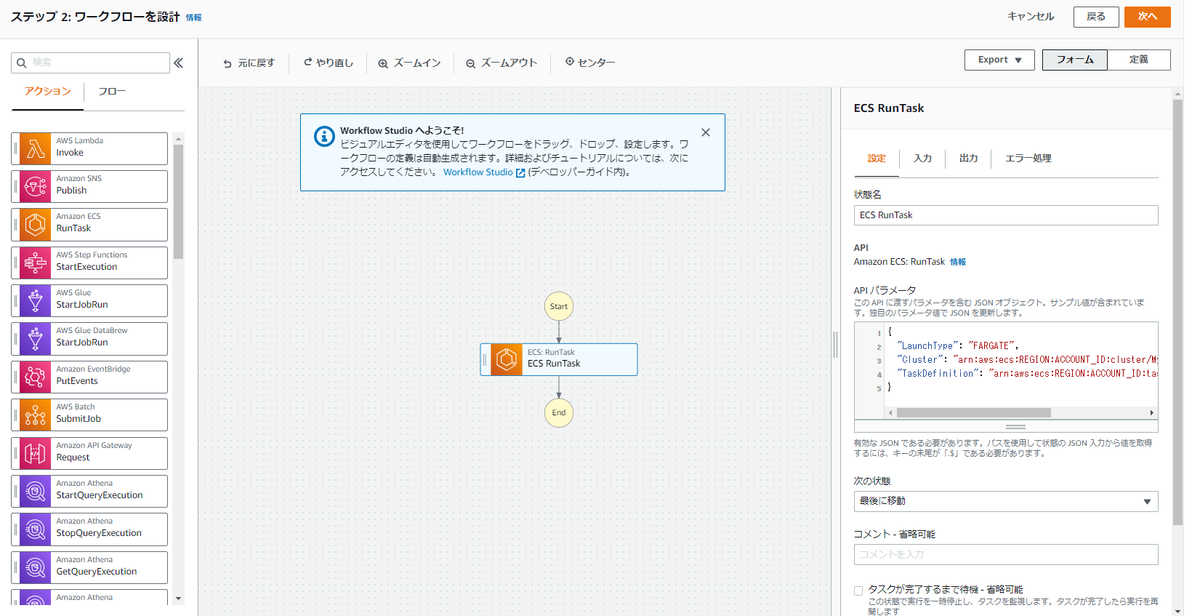
②右パネルの「設定」タブの「APIパラメータ」に以下のjsonを入力(<>は読み替えてください)
{ "LaunchType": "FARGATE", "Cluster": "arn:aws:ecs:ap-northeast-1:<アカウントID>:cluster/poc-embulk-ecs-cluster-001", "TaskDefinition": "arn:aws:ecs:ap-northeast-1:<アカウントID>:task-definition/datafound-embulk-001-test_tbl:1", "NetworkConfiguration": { "AwsvpcConfiguration": { "AssignPublicIp": "ENABLED", "SecurityGroups": [ "<セキュリティグループID>" ], "Subnets": [ "<サブネットID>" ] } } }
設定パラメータに関しては以下のドキュメントを参照してください。
Amazon ECS またはStep Functions で Fargate タスクを管理する - AWS Step Functions
③「タスクが完了するまで待機 - 省略可能」にチェックを入れる
※他はデフォルトのままでOKです。もし興味があれば、エラー時に通知するような設定を組み合わせてみてもいいかもしれません。
右のタスクの設定パネルの「エラー処理」タブで、「+新しいエラーキャッチャーを追加」でエラー処理を追加することができます。
「Errors」でキャッチするエラーを選び、Fallback stateで次のステートを選びます。ここで「SNS Publish」を選択してあげることで、ECS RunTaskの処理が失敗した際にメール通知・Slack通知ができる仕組みを組み込むことができます。
④右上の「次へ」をクリック
3. 【生成されたコードを確認 - 省略可能】
GUIで生成したフローが設定されています。そのまま次へ進みましょう。
4. 【ステートマシン設定を指定】
・ステートマシン名:(好きな名前でOK)
・実行ロール:新しいロールの作成
※残りはデフォルトの設定で問題ないです。(変えてもいいです。)
入力したら、「ステートマシンの作成」をクリックします。
4-3) ステートマシンに設定したAMロールに不足する権限を追加します。
あえて、失敗させた方が衝撃があって覚えやすいと思うので、この状態でいったんステートマシンを実行してみましょう。
作成したステートマシンのページで「実行の開始」をクリックします。入力は使わないのでそのまま「実行の開始」をクリックします(秒で失敗します。)"実行の開始"って機械翻訳っぽい残念な日本語( ̄▽ ̄)
エラーの詳細を確認してみましょう。中央の「グラフインスペクター」で失敗した「ECS RunTask」をクリックします。「例外」タブにエラーの内容が表示されます。ここでiam:PassRoleの権限がないよって言ってくれています。実はパート3でも言及していたECSを実行する際にiam:PassRoleが必要で詰まったといっていたのはこの件です。
それでは、IAMポリシーを追加しましょう。
ステートマシンに割り当てているIAMロールに以下のポリシーを新たに作って割り当てます。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "*" } ] }
※【補足】ベストプラクティス的にはResource句は制限するべきです。制限する場合は2つのロールのARNを指定します。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "iam:PassRole", "Resource": [ "arn:aws:iam::<アカウントID>:role/<タスク実行ロール>", "arn:aws:iam::<アカウントID>:role/<タスクロール>" ] } ] }
ポリシーを付与したら再度ステートマシンを実行します。
実行完了したら、ターゲットデータベースに接続して、以下のSQLでデータが連携されている確認してみましょう。
SELECT * FROM test_target_tbl;
最終的にはこうなっています。
target=> SELECT * FROM test_target_tbl ; id | payload | updated_at ----+-----------------------+------------------------------- 1 | test | 2021-09-19 14:40:27.784264+00 2 | test | 2021-09-19 14:40:27.79379+00 3 | test | 2021-09-19 14:40:27.805231+00 4 | test | 2021-09-19 14:40:27.809595+00 5 | test | 2021-09-19 14:40:30.601724+00 6 | increment_test | 2021-09-20 09:53:14.794196+00 1 | update increment test | 2021-09-20 10:06:58.971426+00 (7 rows)
以上でチュートリアルは完了です。
4-4) 後片付け
後片付けまでがチュートリアルです!お金取られちゃうのでね(-_-;)
とはいえ、基本的にサーバレス基盤で作っているので掘っておく分にはそれほど大きくお金はとられないので、振り返り用に一定期間残しておいて、追加の検証などもやっていくのも面白いかと思います。ただし、RDSは放置しておくと7日後に勝手に起動しちゃうので消しましょう。
【絶対片付けておきたいリソース】
・RDS
【使わなくても課金が発生するリソース(無料枠におさまるかも?)】
・Cloud9のEC2のEBS
・CodeCommit
・S3
・ECR
・CloudWatch Logs
【その他のほっておいてもいいリソース】
・VPC
・セキュリティグループ
・IAMポリシーやIAMAロール、IAMユーザ
・Fargateクラスター
・ECSタスク定義
・Step Functions
最後に
3連休を使って検証からチュートリアル記事の執筆まで行いました。久しぶりに大きめのアウトプットしました!(ちょっと疲れたw)
私はこのチュートリアル環境を残してdbtのコンテナも作ってStep Functionsで組み合わせてELT的なデータ連携パイプラインに昇華させたいなと思っています。サーバレスの基盤はなかなか適応できない領域も多いですが、OSSを組み合わせて使うと本当にコスト最適化された基盤ができるのでこれからも継続して検証していきたいと思います~
本当はコンテナのビルドも含めてCode Deployでやってみたい気もしたのですが、今回はコンテナを使いまわすという戦略を取ったのでビルド自体は1回しか行わないのでCodePipelineに組み込む必要がないなと思ってやめました。dbtの時にはコンテナのビルドも含めてCodeBuildで完全なCI/CDでやりたいと思っています。
その際にはdbtのコンテナビルドに合わせて、dbtのドキュメント部分を静的ウェブサイトホスティングを有効にしたS3にデプロイする処理をかましたいなと思っています。以前に検証した機能も組み合わせてデータ活用基盤の必要な要素の最低限のものがそろっていく感じがワクワクします!
この記事は意外にアクセス数多めの記事なんですよね(*´▽`*)